| Step | Example |
| 1. Place a new (or copied) yml file into /usr/local/etc/filewave/prometheus/conf.d/jobs/https with a meaningful name. | 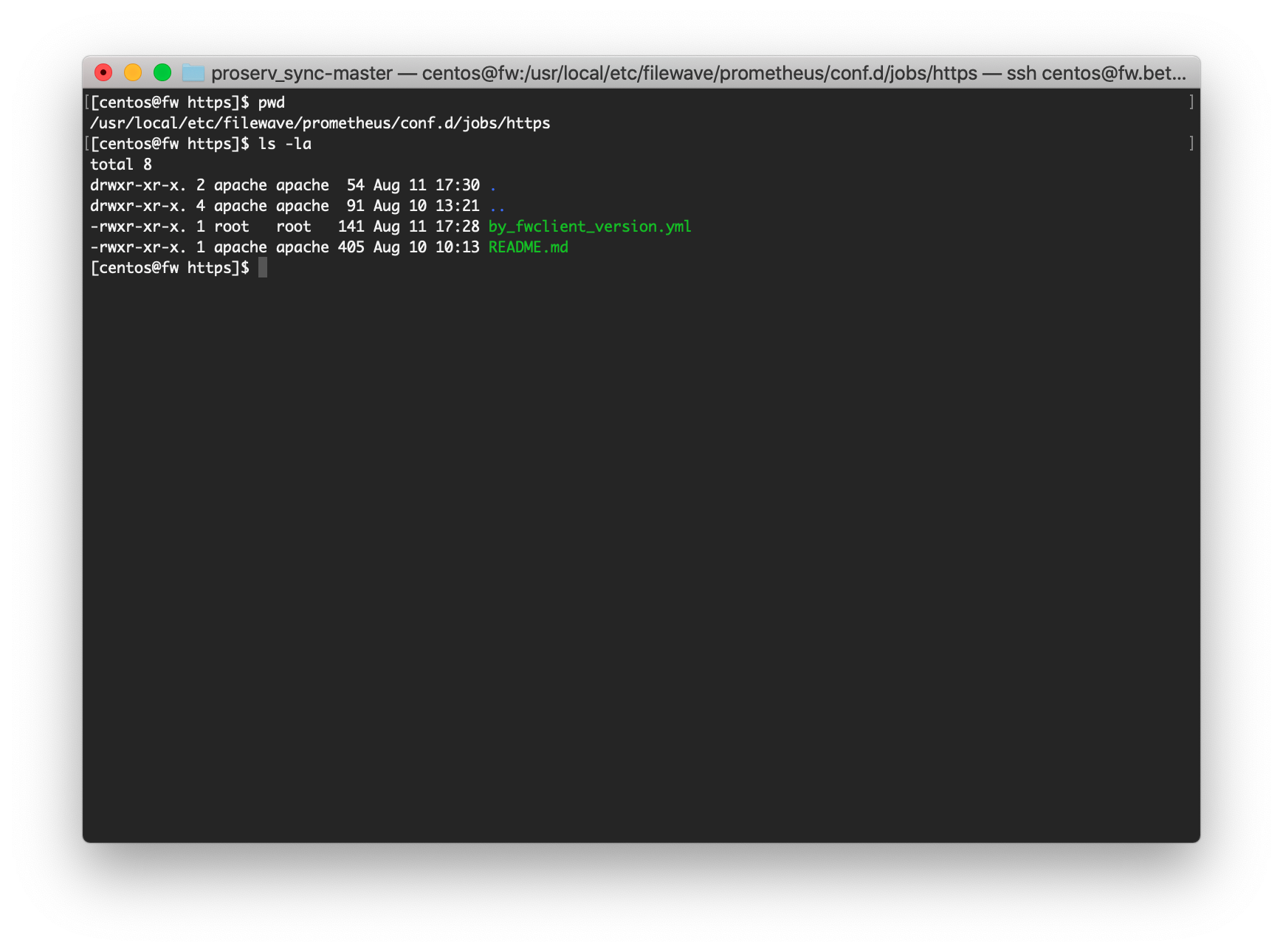 |
| 2. Edit the new file to specify the following 3 things: \* The inventory query (report) to use \* The field you want to count by...device\_id is almost always a good one if reporting by device \* The field you want summarize (aggregate) by...in this case, the filewave client version | |
| 3. Once your report is created, the report id to use is most easily accessed through the webadmin. Note that the fields you want to use for aggregation must be in the report. | 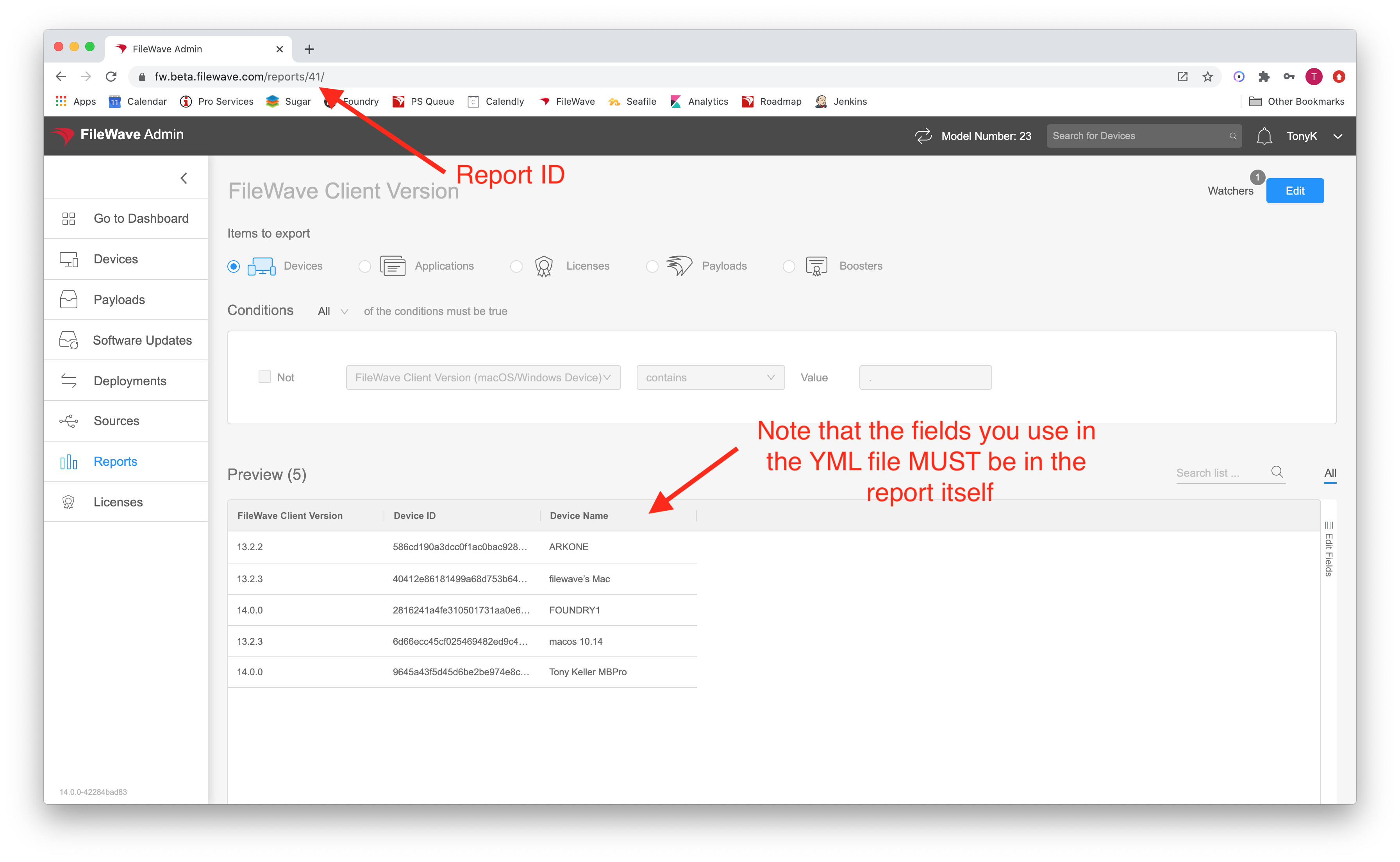 |
| 4. Get the definition for the fields you want to use from the API...the easiest way is to do a curl from the command line like this:
`bash curl -s -k -H "Authorization: ` Make sure and substitute in your values for the <Base64\_API\_Token>, <my.server.address> and <report\_id> You'll get a response that includes the component and the field names as shown at right | 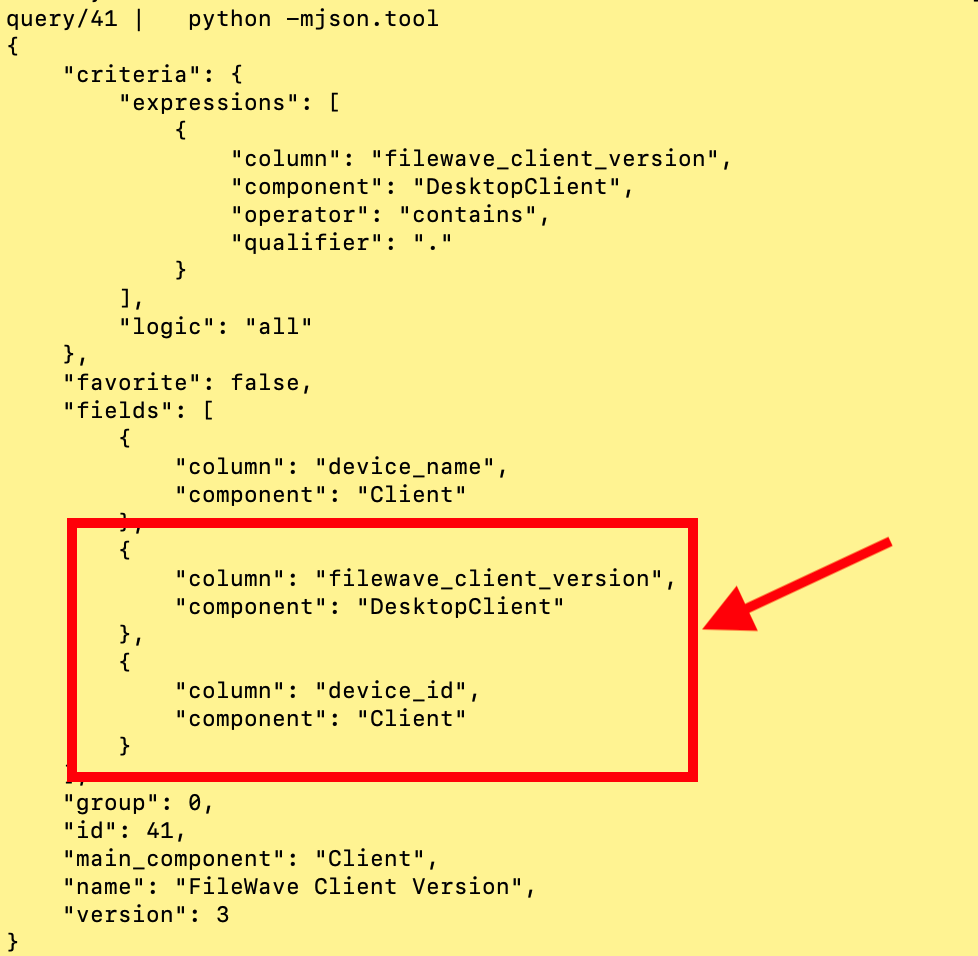 |
| 4. Edit the YML file to specify the 3 items as they match your report definition, then save the file. If using the sample file, remember to take out the comment # at the beginning of each line. Example at right: | 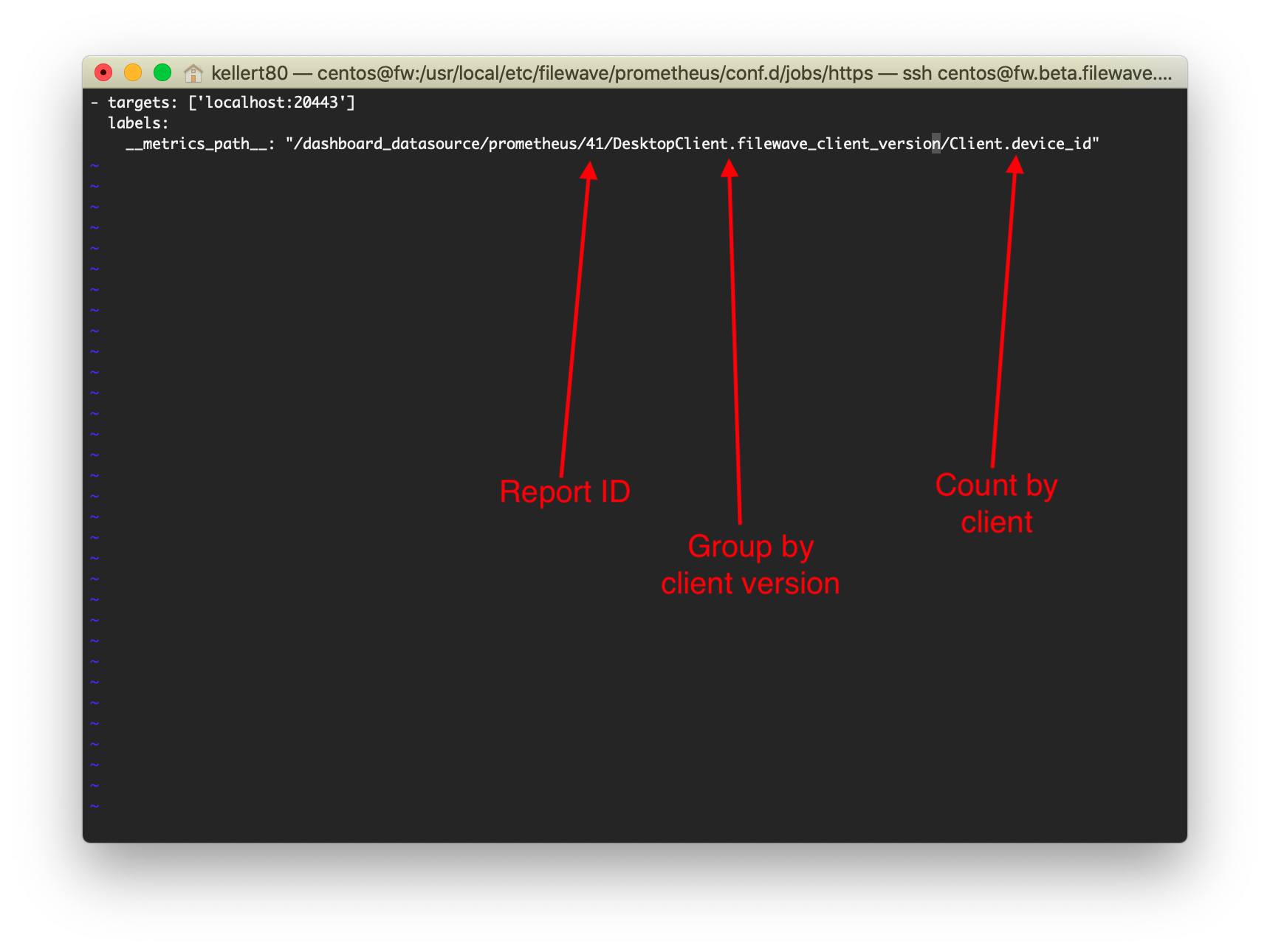 |
| ssh -L 8000:localhost:21090 user@my.server.address |